第2章 神经网络中的三个基本概念⚓︎
2.0 通俗地理解三大概念⚓︎
这三大概念是:反向传播,梯度下降,损失函数。
神经网络训练的最基本的思想就是:先“猜”一个结果,称为预测结果 a,看看这个预测结果和事先标记好的训练集中的真实结果 y 之间的差距,然后调整策略,再试一次,这一次就不是“猜”了,而是有依据地向正确的方向靠近。如此反复多次,一直到预测结果和真实结果之间相差无几,亦即 |a-y|\rightarrow 0,就结束训练。
在神经网络训练中,我们把“猜”叫做初始化,可以随机,也可以根据以前的经验给定初始值。即使是“猜”,也是有技术含量的。
这三个概念是前后紧密相连的,讲到一个,肯定会牵涉到另外一个。但由于损失函数篇幅较大,我们将在下一章中再详细介绍。
下面我们举几个例子来直观的说明下这三个概念。
2.0.1 例一:猜数⚓︎
甲乙两个人玩儿猜数的游戏,数字的范围是 [1,50]:
甲:我猜5
乙:太小了
甲:50
乙:有点儿大
甲:30
乙:小了
......
在这个游戏里:
- 目的:猜到乙心中的数字;
- 初始化:甲猜5;
- 前向计算:甲每次猜的新数字;
- 损失函数:乙在根据甲猜的数来和自己心中想的数做比较,得出“大了”或“小了”的结论;
- 反向传播:乙告诉甲“小了”、“大了”;
- 梯度下降:甲根据乙的反馈中的含义自行调整下一轮的猜测值。
这里的损失函数是什么呢?就是“太小了”,“有点儿大”,很不精确!这个“所谓的”损失函数给出了两个信息:
- 方向:大了或小了
- 程度:“太”,“有点儿”,但是很模糊
2.0.2 例二:黑盒子⚓︎
假设有一个黑盒子如图2-1。
图2-1 黑盒子
我们只能看到输入和输出的数值,看不到里面的样子,当输入1时,输出2.334,然后黑盒子有个信息显示:我需要输出值是4。然后我们试了试输入2,结果输出5.332,一下子比4大了很多。那么我们第一次的损失值是 2.334-4=-1.666,而二次的损失值是 5.332-4=1.332。
这里,我们的损失函数就是一个简单的减法,用实际值减去目标值,但是它可以告诉你两个信息:1)方向,是大了还是小了;2)差值,是0.1还是1.1。这样就给了我们下一次猜的依据。
- 目的:猜到一个输入值,使得黑盒子的输出是4;
- 初始化:输入1;
- 前向计算:黑盒子内部的数学逻辑;
- 损失函数:在输出端,用输出值减4;
- 反向传播:告诉猜数的人差值,包括正负号和值;
- 梯度下降:在输入端,根据正负号和值,确定下一次的猜测值。
2.0.3 例三:打靶⚓︎
小明拿了一支步枪,射击100米外的靶子。这支步枪没有准星,或者是准星有问题,或者是小明眼神儿不好看不清靶子,或者是雾很大,或者风很大,或者由于木星的影响而侧向引力场异常......反正就是遇到各种干扰因素。
第一次试枪后,拉回靶子一看,弹着点偏左了,于是在第二次试枪时,小明就会有意识地向右侧偏几毫米,再看靶子上的弹着点,如此反复几次,小明就会掌握这支步枪的脾气了。图2-2显示了小明的5次试枪过程。
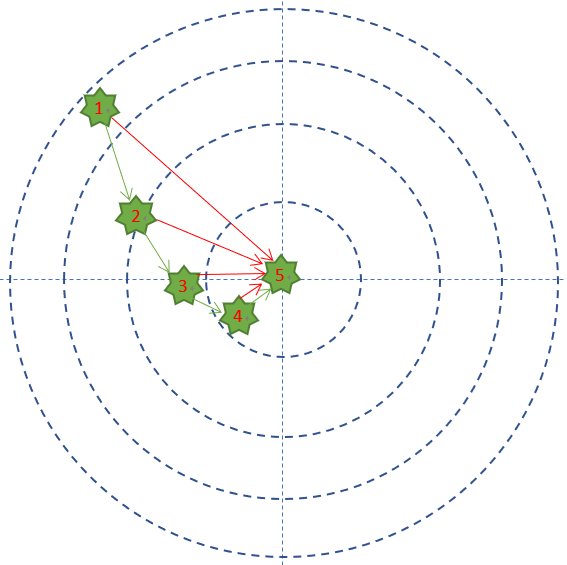
图2-2 打靶的弹着点记录
在有监督的学习中,需要衡量神经网络输出和所预期的输出之间的差异大小。这种误差函数需要能够反映出当前网络输出和实际结果之间一种量化之后的不一致程度,也就是说函数值越大,反映出模型预测的结果越不准确。
这个例子中,小明预期的目标是全部命中靶子的中心,最外圈是1分,之后越向靶子中心分数是2,3,4分,正中靶心可以得10分。
- 每次试枪弹着点和靶心之间的差距就叫做误差,可以用一个误差函数来表示,比如差距的绝对值,如图中的红色线。
- 一共试枪5次,就是迭代/训练了5次的过程 。
- 每次试枪后,把靶子拉回来看弹着点,然后调整下一次的射击角度的过程,叫做反向传播。注意,把靶子拉回来看和跑到靶子前面去看有本质的区别,后者容易有生命危险,因为还有别的射击者。一个不恰当的比喻是,在数学概念中,人跑到靶子前面去看,叫做正向微分;把靶子拉回来看,叫做反向微分。
- 每次调整角度的数值和方向,叫做梯度。比如向右侧调整1毫米,或者向左下方调整2毫米。如图中的绿色矢量线。
上图是每次单发点射,所以每次训练样本的个数是1。在实际的神经网络训练中,通常需要多个样本,做批量训练,以避免单个样本本身采样时带来的误差。在本例中,多个样本可以描述为连发射击,假设一次可以连打3发子弹,每次的离散程度都类似,如图2-3所示。
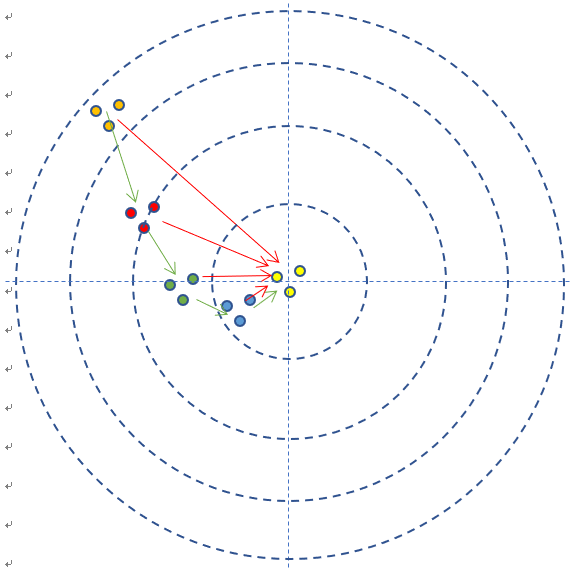
图2-3 连发弹着点记录
- 如果每次3发子弹连发,这3发子弹的弹着点和靶心之间的差距之和再除以3,叫做损失,可以用损失函数来表示。
那小明每次射击结果和目标之间的差距是多少呢?在这个例子里面,用得分来衡量的话,就是说小明得到的反馈结果从差9分,到差8分,到差2分,到差1分,到差0分,这就是用一种量化的结果来表示小明的射击结果和目标之间差距的方式。也就是误差函数的作用。因为是一次只有一个样本,所以这里采用的是误差函数的称呼。如果一次有多个样本,就要叫做损失函数了。
其实射击还不这么简单,如果是远距离狙击,还要考虑空气阻力和风速,在神经网络里,空气阻力和风速可以对应到隐藏层的概念上。
在这个例子中:
- 目的:打中靶心;
- 初始化:随便打一枪,能上靶就行,但是要记住当时的步枪的姿态;
- 前向计算:让子弹飞一会儿,击中靶子;
- 损失函数:环数,偏离角度;
- 反向传播:把靶子拉回来看;
- 梯度下降:根据本次的偏差,调整步枪的射击角度。
损失函数的描述是这样的:
- 1环,偏左上45度;
- 6环,偏左上15度;
- 7环,偏左;
- 8环,偏左下15度;
- 10环。
这里的损失函数也有两个信息:
- 距离;
- 方向。
所以,梯度,是个矢量! 它应该即告诉我们方向,又告诉我们数值。
2.0.4 黑盒子的真正玩法⚓︎
以上三个例子比较简单,容易理解,我们把黑盒子再请出来:黑盒子这件事真正的意义并不是猜测当输入是多少时输出会是4。它的实际意义是:我们要破解这个黑盒子!于是,我们会有如下破解流程:
- 记录下所有输入值和输出值,如表2-1。
表2-1 样本数据表
| 样本ID | 输入(特征值) | 输出(标签) |
|---|---|---|
| 1 | 1 | 2.21 |
| 2 | 1.1 | 2.431 |
| 3 | 1.2 | 2.652 |
| 4 | 2 | 4.42 |
- 搭建一个神经网络,给出初始权重值,我们先假设这个黑盒子的逻辑是:z=x + x^2;
- 输入1,根据 z=x + x^2 得到输出为2,而实际的输出值是2.21,则误差值为 2-2.21=-0.21,小了;
- 调整权重值,比如 z=1.5x+x^2,再输入1.1,得到的输出为2.86,实际输出为2.431,则误差值为 2.86-2.431=0.429,大了;
- 调整权重值,比如 z=1.2x+x^2,再输入1.2……
- 调整权重值,再输入2……
- 所有样本遍历一遍,计算平均的损失函数值;
- 依此类推,重复3,4,5,6过程,直到损失函数值小于一个指标,比如 0.001,我们就可以认为网络训练完毕,黑盒子“破解”了,实际是被复制了,因为神经网络并不能得到黑盒子里的真实函数体,而只是近似模拟。
从上面的过程可以看出,如果误差值是正数,我们就把权重降低一些;如果误差值为负数,则升高权重。
2.0.5 总结⚓︎
简单总结一下反向传播与梯度下降的基本工作原理:
- 初始化;
- 正向计算;
- 损失函数为我们提供了计算损失的方法;
- 梯度下降是在损失函数基础上向着损失最小的点靠近而指引了网络权重调整的方向;
- 反向传播把损失值反向传给神经网络的每一层,让每一层都根据损失值反向调整权重;
- Go to 2,直到精度足够好(比如损失函数值小于 0.001)。