第17章 卷积神经网络原理⚓︎
17.0 卷积神经网络概述⚓︎
17.0.1 卷积神经网络的能力⚓︎
卷积神经网络(CNN,Convolutional Neural Net)是神经网络的类型之一,在图像识别和分类领域中取得了非常好的效果,比如识别人脸、物体、交通标识等,这就为机器人、自动驾驶等应用提供了坚实的技术基础。
在下面图17-1^{[1]}和图17-2中^{[1]},卷积神经网络展现了识别人类日常生活中的各种物体的能力。

图17-1 识别出四个人在一条船上
 |
|
图17-2 识别出一个农场中的车、狗、马、人等物体
下面的场景要比前一个更有趣一些。

图17-3 两匹斑马

图17-4 两个骑车人
卷积神经网络可以识别出上面两张图中的物体和场景,图17-3^{[2]}是“两匹斑马站在泥地上”,图17-4^{[2]}是“一个在道路上骑车的男人旁边还有个女人”。当然,识别物体和给出简要的场景描述是两套系统配合才能完成的任务,第一个系统只负责识别,第二个系统可以根据第一个系统的输出形成摘要文字。
17.0.2 卷积神经网络的典型结构⚓︎
一个典型的卷积神经网络的结构如图17-5所示。
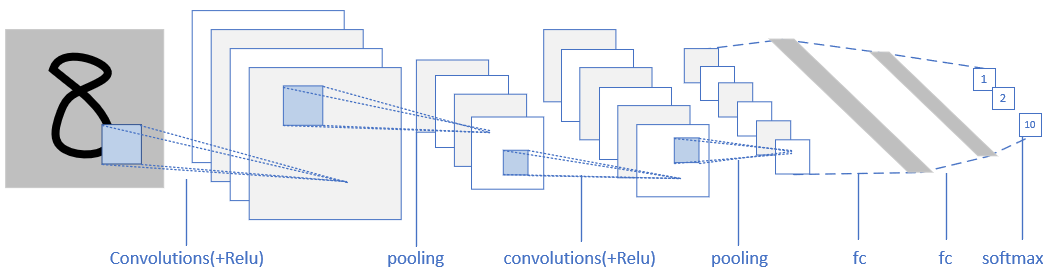
图17-5 卷积神经网络的典型结构图
我们分析一下它的层级结构:
- 原始的输入是一张图片,可以是彩色的,也可以是灰度的或黑白的。这里假设是只有一个通道的图片,目的是识别0~9的手写体数字;
- 第一层卷积,我们使用了4个卷积核,得到了4张feature map;激活函数层没有单独画出来,这里我们紧接着卷积操作使用了Relu激活函数;
- 第二层是池化,使用了Max Pooling方式,把图片的高宽各缩小一倍,但仍然是4个feature map;
- 第三层卷积,我们使用了4x6个卷积核,其中4对应着输入通道,6对应着输出通道,从而得到了6张feature map,当然也使用了Relu激活函数;
- 第四层再次做一次池化,现在得到的图片尺寸只是原始尺寸的四分之一左右;
- 第五层把第四层的6个图片展平成一维,成为一个fully connected层;
- 第六层再接一个小一些的fully connected层;
- 最后接一个softmax函数,判别10个分类。
所以,在一个典型的卷积神经网络中,会至少包含以下几个层:
- 卷积层
- 激活函数层
- 池化层
- 全连接分类层
我们会在后续的小节中讲解卷积层和池化层的具体工作原理。
17.0.3 卷积核的作用⚓︎
我们遇到了一个新的概念:卷积核。卷积网络之所以能工作,完全是卷积核的功劳。什么是卷积核呢?卷积核其实就是一个小矩阵,类似这样:
1.1 0.23 -0.45
0.1 -2.1 1.24
0.74 -1.32 0.01
这是一个3x3的卷积核,还会有1x1、5x5、7x7、9x9、11x11的卷积核。在卷积层中,我们会用输入数据与卷积核相乘,得到输出数据,就类似全连接层中的Weights一样,所以卷积核里的数值,也是通过反向传播的方法学习到的。
下面我们看看卷积核的具体作用。
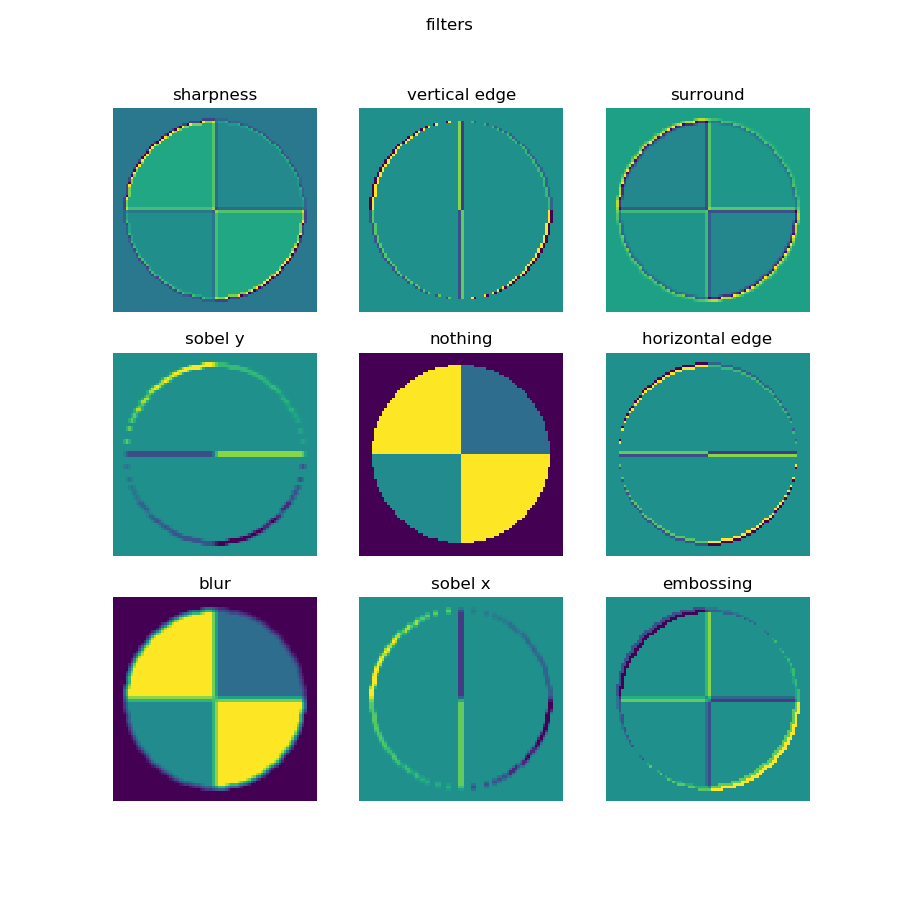
图17-6 卷积核的作用
图17-6中所示的内容,是使用9个不同的卷积核在同一张图上运算后得到的结果,而表17-1中按顺序列出了9个卷积核的数值和名称,可以一一对应到上面的9张图中。
表17-1 卷积的效果
| 1 | 2 | 3 | |
|---|---|---|---|
| 1 | 0,-1, 0 -1, 5,-1 0,-1, 0 |
0, 0, 0 -1, 2,-1 0, 0, 0 |
1, 1, 1 1,-9, 1 1, 1, 1 |
| sharpness | vertical edge | surround | |
| 2 | -1,-2, -1 0, 0, 0 1, 2, 1 |
0, 0, 0 0, 1, 0 0, 0, 0 |
0,-1, 0 0, 2, 0 0,-1, 0 |
| sobel y | nothing | horizontal edge | |
| 3 | 0.11,0.11,0.11 0.11,0.11,0.11 0.11,0.11,0.11 |
-1, 0, 1 -2, 0, 2 -1, 0, 1 |
2, 0, 0 0,-1, 0 0, 0,-1 |
| blur | sobel x | embossing |
我们先说中间那个图,就是第5个卷积核,叫做"nothing"。为什么叫nothing呢?因为这个卷积核在与原始图片计算后得到的结果,和原始图片一模一样,所以我们看到的图5就是相当于原始图片,放在中间是为了方便和其它卷积核的效果做对比。
下面说明9个卷积核的作用:
表17-2 各个卷积核的作用
| 序号 | 名称 | 说明 |
|---|---|---|
| 1 | 锐化 | 如果一个像素点比周围像素点亮,则此算子会令其更亮 |
| 2 | 检测竖边 | 检测出了十字线中的竖线,由于是左侧和右侧分别检查一次,所以得到两条颜色不一样的竖线 |
| 3 | 周边 | 把周边增强,把同色的区域变弱,形成大色块 |
| 4 | Sobel-Y | 纵向亮度差分可以检测出横边,与横边检测不同的是,它可以使得两条横线具有相同的颜色,具有分割线的效果 |
| 5 | Identity | 中心为1四周为0的过滤器,卷积后与原图相同 |
| 6 | 横边检测 | 检测出了十字线中的横线,由于是上侧和下侧分别检查一次,所以得到两条颜色不一样的横线 |
| 7 | 模糊 | 通过把周围的点做平均值计算而“杀富济贫”造成模糊效果 |
| 8 | Sobel-X | 横向亮度差分可以检测出竖边,与竖边检测不同的是,它可以使得两条竖线具有相同的颜色,具有分割线的效果 |
| 9 | 浮雕 | 形成大理石浮雕般的效果 |
17.0.4 卷积后续的运算⚓︎
前面我们认识到了卷积核的强大能力,卷积神经网络通过反向传播而令卷积核自我学习,找到分布在图片中的不同的feature,最后形成的卷积核中的数据。但是如果想达到这种效果,只有卷积层的话是不够的,还需要激活函数、池化等操作的配合。
图17-7中的四个子图,依次展示了:
- 原图
- 卷积结果
- 激活结果
- 池化结果
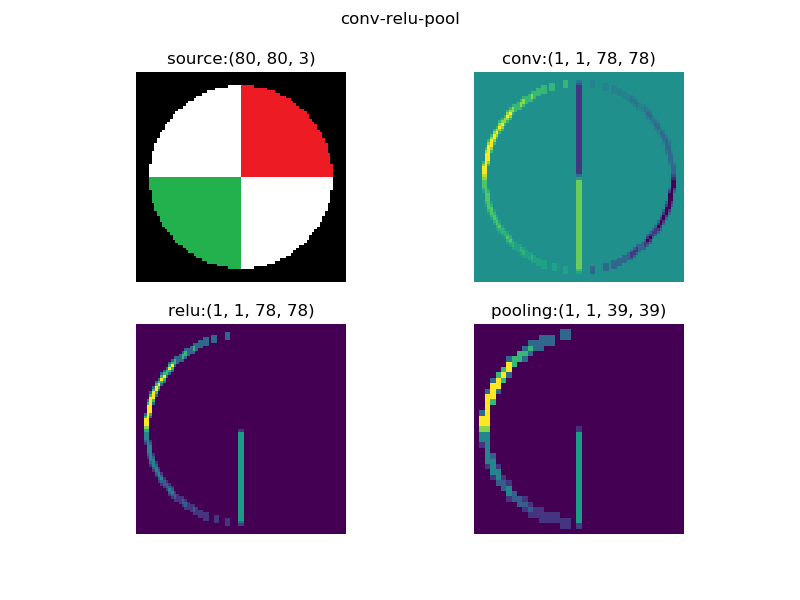
图17-7 原图经过卷积-激活-池化操作后的效果
-
注意图一是原始图片,用cv2读取出来的图片,其顺序是反向的,即:
-
第一维是高度
- 第二维是宽度
-
第三维是彩色通道数,但是其顺序为BGR,而不是常用的RGB
-
我们对原始图片使用了一个3x1x3x3的卷积核,因为原始图片为彩色图片,所以第一个维度是3,对应RGB三个彩色通道;我们希望只输出一张feature map,以便于说明,所以第二维是1;我们使用了3x3的卷积核,用的是sobel x算子。所以图二是卷积后的结果。
-
图三做了一层Relu激活计算,把小于0的值都去掉了,只留下了一些边的特征。
-
图四是图三的四分之一大小,虽然图片缩小了,但是特征都没有丢失,反而因为图像尺寸变小而变得密集,亮点的密度要比图三大而粗。
17.0.5 卷积神经网络的学习⚓︎
从17.0.2节中的整体图中,可以看到在卷积-池化等一些列操作的后面,要接全连接层,这里的全连接层和我们在前面学习的深度网络的功能一模一样,都是做为分类层使用。
在最后一层的池化后面,把所有特征数据变成一个一维的全连接层,然后就和普通的深度全连接网络一样了,通过在最后一层的softmax分类函数,以及多分类交叉熵函数,对比图片的OneHot编码标签,回传误差值,从全连接层传回到池化层,通过激活函数层再回传给卷积层,对卷积核的数值进行梯度更新,实现卷积核数值的自我学习。
但是这里有个问题,回忆一下MNIST数据集,所有的样本数据都是处于28x28方形区域的中间地带,如下图中的左上角的图片A所示。
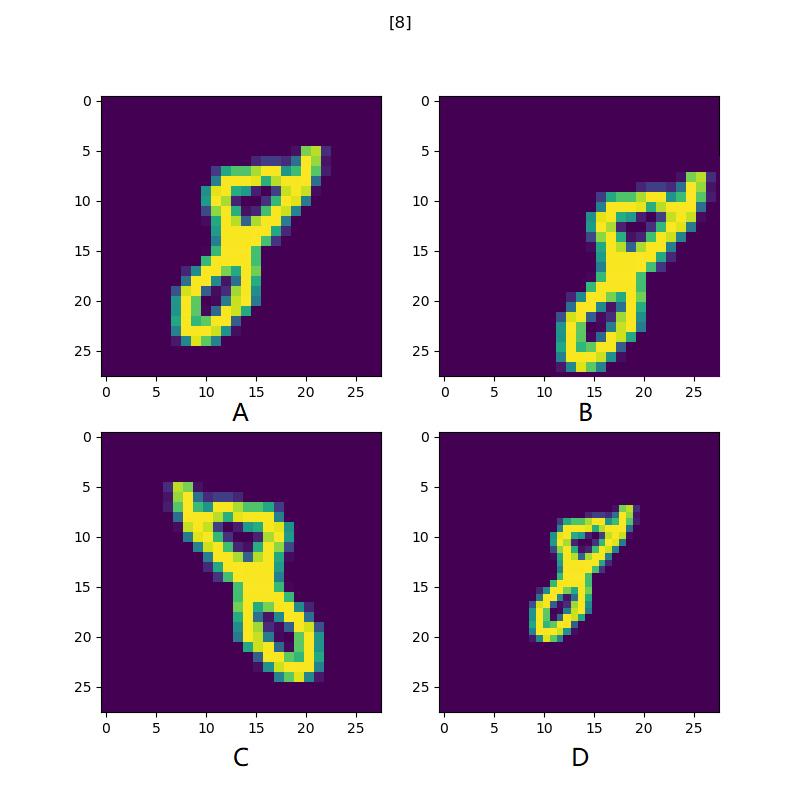
图17-8 同一个背景下数字8的大小、位置、形状的不同
我们的问题是:
- 如果这个“8”的位置很大地偏移到了右下角,使得左侧留出来一大片空白,即发生了平移,如上图右上角子图B
- “8”做了一些旋转或者翻转,即发生了旋转视角,如上图左下角子图C
- “8”缩小了很多或放大了很多,即发生了尺寸变化,如上图右下角子图D
尽管发生了变化,但是对于人类的视觉系统来说都可以轻松应对,即平移不变性、旋转视角不变性、尺度不变性。那么卷积神经网络网络如何处理呢?
- 平移不变性
对于原始图A,平移后得到图B,对于同一个卷积核来说,都会得到相同的特征,这就是卷积核的权值共享。但是特征处于不同的位置,由于距离差距较大,即使经过多层池化后,也不能处于近似的位置。此时,后续的全连接层会通过权重值的调整,把这两个相同的特征看作同一类的分类标准之一。如果是小距离的平移,通过池化层就可以处理了。
- 旋转不变性
对于原始图A,有小角度的旋转得到C,卷积层在A图上得到特征a,在C图上得到特征c,可以想象a与c的位置间的距离不是很远,在经过两层池化以后,基本可以重合。所以卷积网络对于小角度旋转是可以容忍的,但是对于较大的旋转,需要使用数据增强来增加训练样本。一个极端的例子是当6旋转90度时,谁也不能确定它到底是6还是9。
- 尺度不变性
对于原始图A和缩小的图D,人类可以毫不费力地辨别出它们是同一个东西。池化在这里是不是有帮助呢?没有!因为神经网络对A做池化的同时,也会用相同的方法对D做池化,这样池化的次数一致,最终D还是比A小。如果我们有多个卷积视野,相当于从两米远的地方看图A,从一米远的地方看图D,那么A和D就可以很相近似了。这就是Inception的想法,用不同尺寸的卷积核去同时寻找同一张图片上的特征。
代码位置⚓︎
ch17, Level0
参考资料⚓︎
[1] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun, Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Link: https://arxiv.org/pdf/1506.01497v3.pdf
[2] https://cs.stanford.edu/people/karpathy/neuraltalk2/demo.html and https://ujjwalkarn.me/2016/08/11/intuitive-explanation-convnets/