第10章 多入单出的双层神经网络 - 非线性二分类⚓︎
10.0 非线性二分类问题⚓︎
10.0.1 提出问题一:异或问题⚓︎
在1969年,一本著名的书《Perceptrons》(感知器,Minsky、Papert,1969)证明了无法使用单层网络(当时称为感知器)来表示最基本的异或逻辑功能。这本书带来了毁灭性的影响,对于感知机这一新生领域的资金支持及兴趣都消失了。
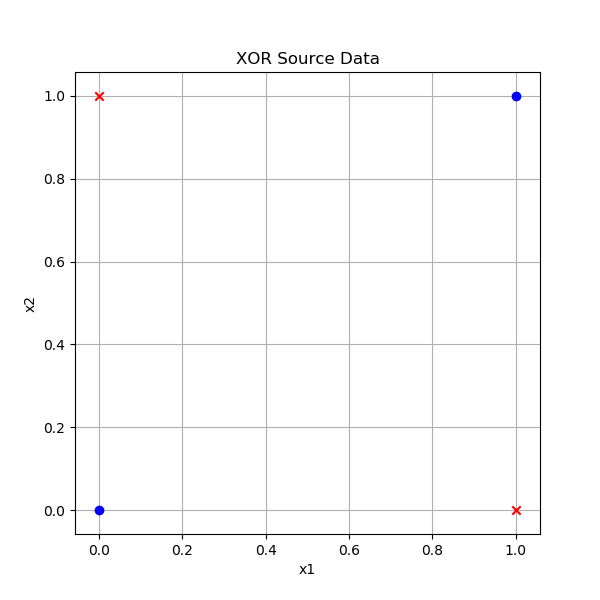
图10-1 异或问题的样本数据
从图10-1看,两类样本点(红色叉子和蓝色圆点)交叉分布在[0,1]空间的四个角上,用一条直线无法分割开两类样本。神经网络是建立在感知器的基础上的,那么我们用神经网络如何解决异或问题呢?
10.0.2 提出问题二:双弧形问题⚓︎
我们给出一个比异或问题要稍微复杂些的问题,如图10-2所示。
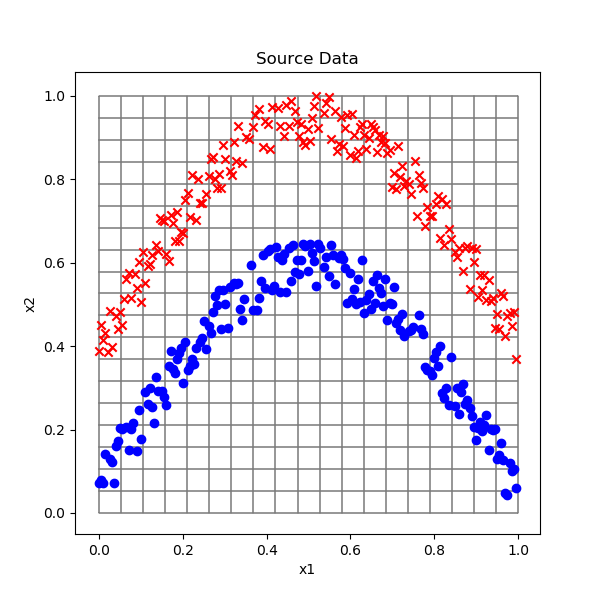
图10-2 呈弧线分布的两类样本数据
平面上有两类样本数据,都成弧形分布,由于弧度的存在,使得我们无法使用一根直线来分开红蓝两种样本点,那么神经网络能用一条曲线来分开它们吗?
10.0.3 二分类模型的评估标准⚓︎
准确率 Accuracy⚓︎
也可以称之为精度,我们在本书中混用这两个词。
对于二分类问题,假设测试集上一共1000个样本,其中550个正例,450个负例。测试一个模型时,得到的结果是:521个正例样本被判断为正类,435个负例样本被判断为负类,则正确率计算如下:
即正确率为95.6%。这种方式对多分类也是有效的,即三类中判别正确的样本数除以总样本数,即为准确率。
但是这种计算方法丢失了很多细节,比如:是正类判断的精度高还是负类判断的精度高呢?因此,我们还有如下一种评估标准。
混淆矩阵⚓︎
还是用上面的例子,如果具体深入到每个类别上,会分成4部分来评估:
- 正例中被判断为正类的样本数(TP-True Positive):521
- 正例中被判断为负类的样本数(FN-False Negative):550-521=29
- 负例中被判断为负类的样本数(TN-True Negative):435
- 负例中被判断为正类的样本数(FP-False Positive):450-435=15
可以用图10-3来帮助理解。
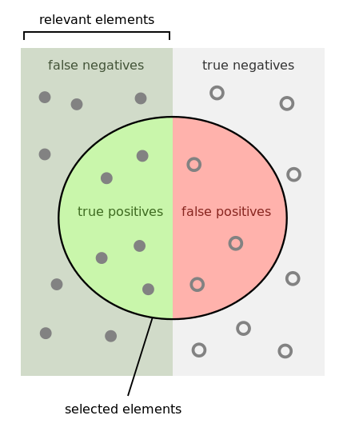
图10-3 二分类中四种类别的示意图
- 左侧实心圆点是正类,右侧空心圆是负类;
- 在圆圈中的样本是被模型判断为正类的,圆圈之外的样本是被判断为负类的;
- 左侧圆圈外的点是正类但是误判为负类,右侧圆圈内的点是负类但是误判为正类;
- 左侧圆圈内的点是正类且被正确判别为正类,右侧圆圈外的点是负类且被正确判别为负类。
用表格的方式描述矩阵的话是表10-1的样子。
表10-1 四类样本的矩阵关系
| 预测值 | 被判断为正类 | 被判断为负类 | Total |
|---|---|---|---|
| 样本实际为正例 | TP-True Positive | FN-False Negative | Actual Positive=TP+FN |
| 样本实际为负例 | FP-False Positive | TN-True Negative | Actual Negative=FP+TN |
| Total | Predicated Postivie=TP+FP | Predicated Negative=FN+TN |
从混淆矩阵中可以得出以下统计指标:
- 准确率 Accuracy
这个指标就是上面提到的准确率,越大越好。
- 精确率/查准率 Precision
分子为被判断为正类并且真的是正类的样本数,分母是被判断为正类的样本数。越大越好。
- 召回率/查全率 Recall
分子为被判断为正类并且真的是正类的样本数,分母是真的正类的样本数。越大越好。
- TPR - True Positive Rate 真正例率
- FPR - False Positive Rate 假正例率
分子为被判断为正类的负例样本数,分母为所有负类样本数。越小越好。
- 调和平均值 F1
该值越大越好。
- ROC曲线与AUC
ROC,Receiver Operating Characteristic,接收者操作特征,又称为感受曲线(Sensitivity Curve),是反映敏感性和特异性连续变量的综合指标,曲线上各点反映着相同的感受性,它们都是对同一信号刺激的感受性。 ROC曲线的横坐标是FPR,纵坐标是TPR。
AUC,Area Under Roc,即ROC曲线下面的面积。
在二分类器中,如果使用Logistic函数作为分类函数,可以设置一系列不同的阈值,比如[0.1,0.2,0.3...0.9],把测试样本输入,从而得到一系列的TP、FP、TN、FN,然后就可以绘制如下曲线,如图10-4。
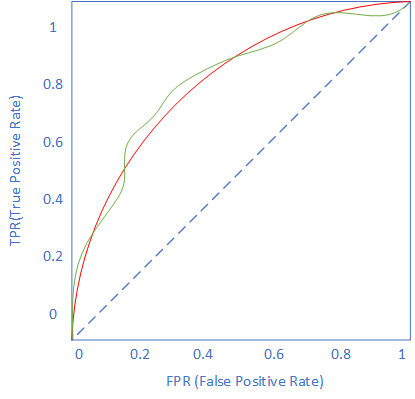
图10-4 ROC曲线图
图中红色的曲线就是ROC曲线,曲线下的面积就是AUC值,取值区间为[0.5,1.0],面积越大越好。
- ROC曲线越靠近左上角,该分类器的性能越好。
- 对角线表示一个随机猜测分类器。
- 若一个学习器的ROC曲线被另一个学习器的曲线完全包住,则可判断后者性能优于前者。
- 若两个学习器的ROC曲线没有包含关系,则可以判断ROC曲线下的面积,即AUC,谁大谁好。
当然在实际应用中,取决于阈值的采样间隔,红色曲线不会这么平滑,由于采样间隔会导致该曲线呈阶梯状。
既然已经这么多标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现样本类不平衡,即正负样本比例差距较大,而且测试数据中的正负样本也可能随着时间变化。
Kappa statics⚓︎
Kappa值,即内部一致性系数(inter-rater,coefficient of internal consistency),是作为评价判断的一致性程度的重要指标。取值在0~1之间。
其中,p_0是每一类正确分类的样本数量之和除以总样本数,也就是总体分类精度。p_e的定义见以下公式。
- Kappa≥0.75两者一致性较好;
- 0.75>Kappa≥0.4两者一致性一般;
- Kappa<0.4两者一致性较差。
该系数通常用于多分类情况,如:
| 实际类别A | 实际类别B | 实际类别C | 预测总数 | |
|---|---|---|---|---|
| 预测类别A | 239 | 21 | 16 | 276 |
| 预测类别B | 16 | 73 | 4 | 93 |
| 预测类别C | 6 | 9 | 280 | 295 |
| 实际总数 | 261 | 103 | 300 | 664 |
数据一致性较好,说明分类器性能好。
Mean absolute error 和 Root mean squared error⚓︎
平均绝对误差和均方根误差,用来衡量分类器预测值和实际结果的差异,越小越好。
Relative absolute error 和 Root relative squared error⚓︎
相对绝对误差和相对均方根误差,有时绝对误差不能体现误差的真实大小,而相对误差通过体现误差占真值的比重来反映误差大小。