06.1 二分类函数
6.1 二分类函数⚓︎
此函数对线性和非线性二分类都适用。
6.1.1 二分类函数⚓︎
对率函数Logistic Function,即可以做为激活函数使用,又可以当作二分类函数使用。而在很多不太正规的文字材料中,把这两个概念混用了,比如下面这个说法:“我们在最后使用Sigmoid激活函数来做二分类”,这是不恰当的。在本书中,我们会根据不同的任务区分激活函数和分类函数这两个概念,在二分类任务中,叫做Logistic函数,而在作为激活函数时,叫做Sigmoid函数。
- Logistic函数公式
以下记 a=Logistic(z)。
- 导数
具体求导过程可以参考8.1节。
- 输入值域
- 输出值域
- 函数图像(图6-2)
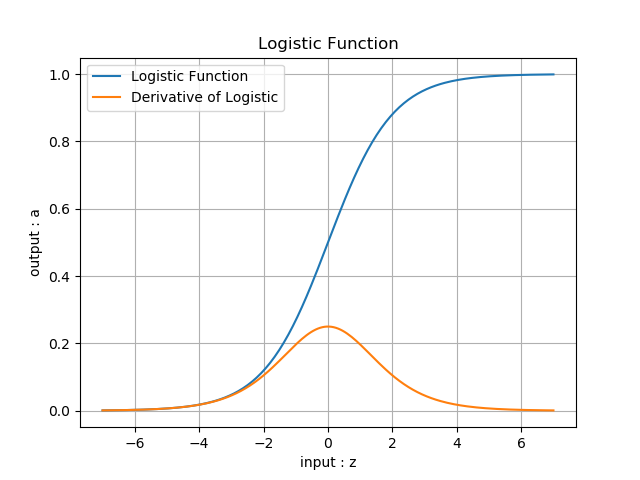
图6-2 Logistic函数图像
- 使用方式
此函数实际上是一个概率计算,它把 (-\infty, \infty) 之间的任何数字都压缩到 (0,1) 之间,返回一个概率值,这个概率值接近 1 时,认为是正例,否则认为是负例。
训练时,一个样本 x 在经过神经网络的最后一层的矩阵运算结果作为输入 z,经过Logistic计算后,输出一个 (0,1) 之间的预测值。我们假设这个样本的标签值为 0 属于负类,如果其预测值越接近 0,就越接近标签值,那么误差越小,反向传播的力度就越小。
推理时,我们预先设定一个阈值比如 0.5,则当推理结果大于 0.5 时,认为是正类;小于 0.5 时认为是负类;等于 0.5 时,根据情况自己定义。阈值也不一定就是 0.5,也可以是 0.65 等等,阈值越大,准确率越高,召回率越低;阈值越小则相反,准确度越低,召回率越高。
比如:
- input=2时,output=0.88,而0.88>0.5,算作正例
- input=-1时,output=0.27,而0.27<0.5,算作负例
6.1.2 正向传播⚓︎
矩阵运算⚓︎
分类计算⚓︎
损失函数计算⚓︎
二分类交叉熵损失函数:
6.1.3 反向传播⚓︎
求损失函数对 a 的偏导⚓︎
求 a 对 z 的偏导⚓︎
求误差 loss 对 z 的偏导⚓︎
使用链式法则链接公式4和公式5:
我们惊奇地发现,使用交叉熵函数求导得到的分母,与Logistic分类函数求导后的结果,正好可以抵消,最后只剩下了 a-y 这一项。真的有这么巧合的事吗?实际上这是依靠科学家们的聪明才智寻找出了这种匹配关系,以满足以下条件:
- 损失函数满足二分类的要求,无论是正例还是反例,都是单调的;
- 损失函数可导,以便于使用反向传播算法;
- 计算过程非常简单,一个减法就可以搞定。
多样本情况⚓︎
我们用三个样本做实例化推导:
所以,用矩阵运算时可以简化为矩阵相减的形式:A-Y。
6.1.4 对数几率的来历⚓︎
经过数学推导后可以知道,神经网络实际也是在做这样一件事:经过调整 w 和 b 的值,把所有正例的样本都归纳到大于 0.5 的范围内,所有负例都小于 0.5。但是如果只说大于或者小于,无法做准确的量化计算,所以用一个对率函数来模拟。
说到对率函数,还有一个问题,它为什么叫做“对数几率”函数呢?
我们举例说明:假设有一个硬币,抛出落地后,得到正面的概率是0.5,得到反面的概率是0.5。如果用正面的概率除以反面的概率,0.5/0.5=1,这个数值叫做odds,即几率。
泛化一下,如果正面的概率是 a,则反面的概率就是 1-a,则几率等于:
上式中,如果 a 是把样本 x 的预测为正例的可能性,那么 1-a 就是其负例的可能性,\frac{a}{1-a}就是正负例的比值,称为几率(odds),它反映了 x作为正例的相对可能性,而对几率取对数就叫做对数几率(log odds, logit)。
假设概率如表6-3。
表6-3 概率到对数几率的对照表
| 概率a | 0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 反概率1-a | 1 | 0.9 | 0.8 | 0.7 | 0.6 | 0.5 | 0.4 | 0.3 | 0.2 | 0.1 | 0 |
| 几率 odds | 0 | 0.11 | 0.25 | 0.43 | 0.67 | 1 | 1.5 | 2.33 | 4 | 9 | \infty |
| 对数几率 \ln(odds) | N/A | -2.19 | -1.38 | -0.84 | -0.4 | 0 | 0.4 | 0.84 | 1.38 | 2.19 | N/A |
可以看到几率的值不是线性的,不利于分析问题,所以在表中第4行对几率取对数,可以得到一组成线性关系的值,并可以用直线方程来表示,即:
对公式10两边取自然指数:
令z=xw+b:
公式12就是公式2!对数几率的函数形式可以认为是这样得到的。
以上推导过程,实际上就是用线性回归模型的预测结果来逼近样本分类的对数几率。这就是为什么它叫做逻辑回归(logistic regression),但其实是分类学习的方法。这种方法的优点如下:
- 把线性回归的成功经验引入到分类问题中,相当于对“分界线”的预测进行建模,而“分界线”在二维空间上是一条直线,这就不需要考虑具体样本的分布(比如在二维空间上的坐标位置),避免了假设分布不准确所带来的问题;
- 不仅预测出类别(0/1),而且得到了近似的概率值(比如0.31或0.86),这对许多需要利用概率辅助决策的任务很有用;
- 对率函数是任意阶可导的凸函数,有很好的数学性,许多数值优化算法都可以直接用于求取最优解。