03.2 交叉熵损失函数
3.2 交叉熵损失函数⚓︎
交叉熵(Cross Entropy)是Shannon信息论中一个重要概念,主要用于度量两个概率分布间的差异性信息。在信息论中,交叉熵是表示两个概率分布 p,q 的差异,其中 p 表示真实分布,q 表示预测分布,那么 H(p,q) 就称为交叉熵:
交叉熵可在神经网络中作为损失函数,p 表示真实标记的分布,q 则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量 p 与 q 的相似性。
交叉熵函数常用于逻辑回归(logistic regression),也就是分类(classification)。
3.2.1 交叉熵的由来⚓︎
信息量⚓︎
信息论中,信息量的表示方式:
x_j:表示一个事件
p(x_j):表示 x_j 发生的概率
I(x_j):信息量,x_j 越不可能发生时,它一旦发生后的信息量就越大
假设对于学习神经网络原理课程,我们有三种可能的情况发生,如表3-2所示。
表3-2 三种事件的概论和信息量
| 事件编号 | 事件 | 概率 p | 信息量 I |
|---|---|---|---|
| x_1 | 优秀 | p=0.7 | I=-\ln(0.7)=0.36 |
| x_2 | 及格 | p=0.2 | I=-\ln(0.2)=1.61 |
| x_3 | 不及格 | p=0.1 | I=-\ln(0.1)=2.30 |
WoW,某某同学不及格!好大的信息量!相比较来说,“优秀”事件的信息量反而小了很多。
熵⚓︎
则上面的问题的熵是:
相对熵(KL散度)⚓︎
相对熵又称KL散度,如果我们对于同一个随机变量 x 有两个单独的概率分布 P(x) 和 Q(x),我们可以使用 KL 散度(Kullback-Leibler (KL) divergence)来衡量这两个分布的差异,这个相当于信息论范畴的均方差。
KL散度的计算公式:
n 为事件的所有可能性。D 的值越小,表示 q 分布和 p 分布越接近。
交叉熵⚓︎
把上述公式变形:
等式的前一部分恰巧就是 p 的熵,等式的后一部分,就是交叉熵:
在机器学习中,我们需要评估标签值 y 和预测值 a 之间的差距,使用KL散度刚刚好,即 D_{KL}(y||a),由于KL散度中的前一部分 H(y) 不变,故在优化过程中,只需要关注交叉熵就可以了。所以一般在机器学习中直接用交叉熵做损失函数来评估模型。
公式7是单个样本的情况,n 并不是样本个数,而是分类个数。所以,对于批量样本的交叉熵计算公式是:
m 是样本数,n 是分类数。
有一类特殊问题,就是事件只有两种情况发生的可能,比如“学会了”和“没学会”,称为 0/1 分类或二分类。对于这类问题,由于n=2,y_1=1-y_2,a_1=1-a_2,所以交叉熵可以简化为:
二分类对于批量样本的交叉熵计算公式是:
3.2.2 二分类问题交叉熵⚓︎
把公式10分解开两种情况,当 y=1 时,即标签值是 1,是个正例,加号后面的项为 0:
横坐标是预测输出,纵坐标是损失函数值。y=1 意味着当前样本标签值是1,当预测输出越接近1时,损失函数值越小,训练结果越准确。当预测输出越接近0时,损失函数值越大,训练结果越糟糕。
当 y=0 时,即标签值是0,是个反例,加号前面的项为0:
此时,损失函数值如图3-10。
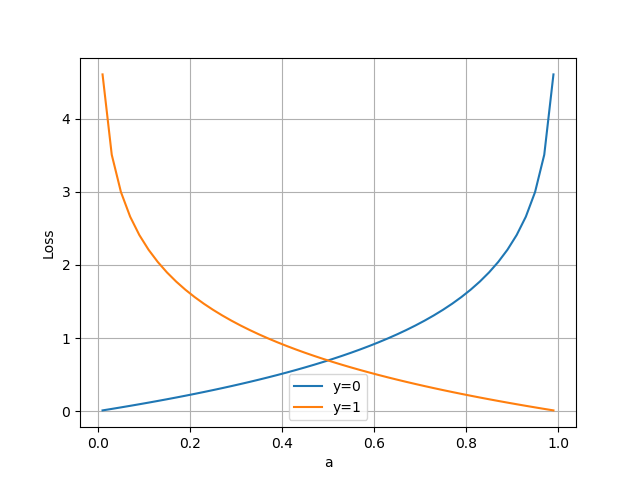
图3-10 二分类交叉熵损失函数图
假设学会了课程的标签值为1,没有学会的标签值为0。我们想建立一个预测器,对于一个特定的学员,根据出勤率、课堂表现、作业情况、学习能力等等来预测其学会课程的概率。
对于学员甲,预测其学会的概率为0.6,而实际上该学员通过了考试,真实值为1。所以,学员甲的交叉熵损失函数值是:
对于学员乙,预测其学会的概率为0.7,而实际上该学员也通过了考试。所以,学员乙的交叉熵损失函数值是:
由于0.7比0.6更接近1,是相对准确的值,所以 loss2 要比 loss1 小,反向传播的力度也会小。
3.2.3 多分类问题交叉熵⚓︎
当标签值不是非0即1的情况时,就是多分类了。假设期末考试有三种情况:
- 优秀,标签值OneHot编码为 [1,0,0];
- 及格,标签值OneHot编码为 [0,1,0];
- 不及格,标签值OneHot编码为 [0,0,1]。
假设我们预测学员丙的成绩为优秀、及格、不及格的概率为:[0.2,0.5,0.3],而真实情况是该学员不及格,则得到的交叉熵是:
假设我们预测学员丁的成绩为优秀、及格、不及格的概率为:[0.2,0.2,0.6],而真实情况是该学员不及格,则得到的交叉熵是:
可以看到,0.51比1.2的损失值小很多,这说明预测值越接近真实标签值(0.6 vs 0.3),交叉熵损失函数值越小,反向传播的力度越小。
3.2.4 为什么不能使用均方差做为分类问题的损失函数?⚓︎
-
回归问题通常用均方差损失函数,可以保证损失函数是个凸函数,即可以得到最优解。而分类问题如果用均方差的话,损失函数的表现不是凸函数,就很难得到最优解。而交叉熵函数可以保证区间内单调。
-
分类问题的最后一层网络,需要分类函数,Sigmoid或者Softmax,如果再接均方差函数的话,其求导结果复杂,运算量比较大。用交叉熵函数的话,可以得到比较简单的计算结果,一个简单的减法就可以得到反向误差。