第3章 损失函数⚓︎
3.0 损失函数概论⚓︎
3.0.1 概念⚓︎
在各种材料中经常看到的中英文词汇有:误差,偏差,Error,Cost,Loss,损失,代价......意思都差不多,在本书中,使用“损失函数”和“Loss Function”这两个词汇,具体的损失函数符号用 J 来表示,误差值用 loss 表示。
“损失”就是所有样本的“误差”的总和,亦即(m 为样本数):
在黑盒子的例子中,我们如果说“某个样本的损失”是不对的,只能说“某个样本的误差”,因为样本是一个一个计算的。如果我们把神经网络的参数调整到完全满足独立样本的输出误差为 0,通常会令其它样本的误差变得更大,这样作为误差之和的损失函数值,就会变得更大。所以,我们通常会在根据某个样本的误差调整权重后,计算一下整体样本的损失函数值,来判定网络是不是已经训练到了可接受的状态。
损失函数的作用⚓︎
损失函数的作用,就是计算神经网络每次迭代的前向计算结果与真实值的差距,从而指导下一步的训练向正确的方向进行。
如何使用损失函数呢?具体步骤:
- 用随机值初始化前向计算公式的参数;
- 代入样本,计算输出的预测值;
- 用损失函数计算预测值和标签值(真实值)的误差;
- 根据损失函数的导数,沿梯度最小方向将误差回传,修正前向计算公式中的各个权重值;
- 进入第2步重复, 直到损失函数值达到一个满意的值就停止迭代。
3.0.2 机器学习常用损失函数⚓︎
符号规则:a 是预测值,y 是样本标签值,loss 是损失函数值。
-
Gold Standard Loss,又称0-1误差 $$ loss=\begin{cases} 0 & a=y \\ 1 & a \ne y \end{cases} $$
-
绝对值损失函数
- Hinge Loss,铰链/折页损失函数或最大边界损失函数,主要用于SVM(支持向量机)中
- Log Loss,对数损失函数,又叫交叉熵损失函数(cross entropy error)
-
Squared Loss,均方差损失函数 $$ loss=(a-y)^2 $$
-
Exponential Loss,指数损失函数 $$ loss = e^{-(y \cdot a)} $$
3.0.3 损失函数图像理解⚓︎
用二维函数图像理解单变量对损失函数的影响⚓︎
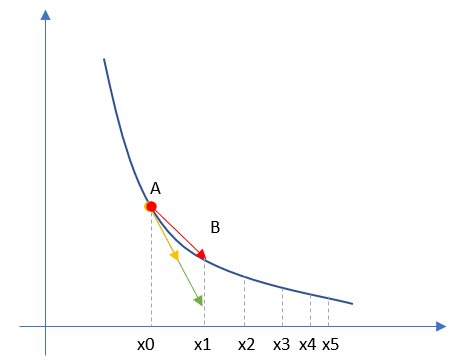
图3-1 单变量的损失函数图
图3-1中,纵坐标是损失函数值,横坐标是变量。不断地改变变量的值,会造成损失函数值的上升或下降。而梯度下降算法会让我们沿着损失函数值下降的方向前进。
- 假设我们的初始位置在 A 点,x=x_0,损失函数值(纵坐标)较大,回传给网络做训练;
- 经过一次迭代后,我们移动到了 B 点,x=x_1,损失函数值也相应减小,再次回传重新训练;
- 以此节奏不断向损失函数的最低点靠近,经历了 x_2,x_3,x_4,x_5;
- 直到损失值达到可接受的程度,比如 x_5 的位置,就停止训练。
用等高线图理解双变量对损失函数影响⚓︎
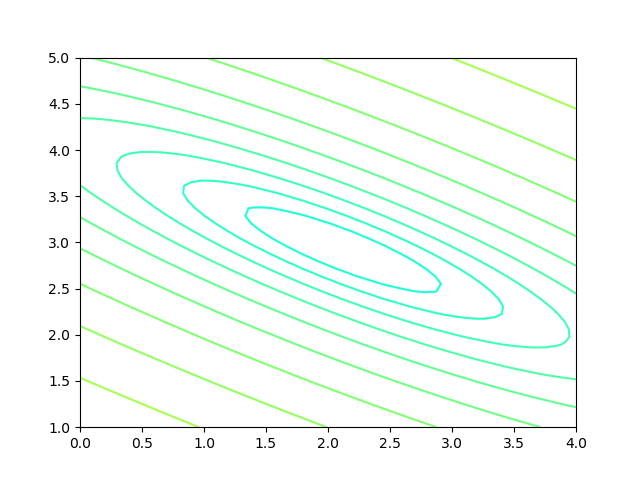
图3-2 双变量的损失函数图
图3-2中,横坐标是一个变量 w,纵坐标是另一个变量 b。两个变量的组合形成的损失函数值,在图中对应处于等高线上的唯一的一个坐标点。w,b 所有不同值的组合会形成一个损失函数值的矩阵,我们把矩阵中具有相同(相近)损失函数值的点连接起来,可以形成一个不规则椭圆,其圆心位置,是损失值为 0 的位置,也是我们要逼近的目标。
这个椭圆如同平面地图的等高线,来表示的一个洼地,中心位置比边缘位置要低,通过对损失函数值的计算,对损失函数的求导,会带领我们沿着等高线形成的梯子一步步下降,无限逼近中心点。
3.0.4 神经网络中常用的损失函数⚓︎
-
均方差函数,主要用于回归
-
交叉熵函数,主要用于分类
二者都是非负函数,极值在底部,用梯度下降法可以求解。