使用HDFS提交任务⚓︎
注意: OpenPAI 部署了一个 HDFS 服务来保存日志和其它文件。 虽然此 HDFS 也可用来存储文件,但**不推荐**这样做。 因为 OpenPAI 集群的服务器可能会频繁增减,磁盘空间也有可能不够,因此无法保证存储的质量。
提交训练任务⚓︎
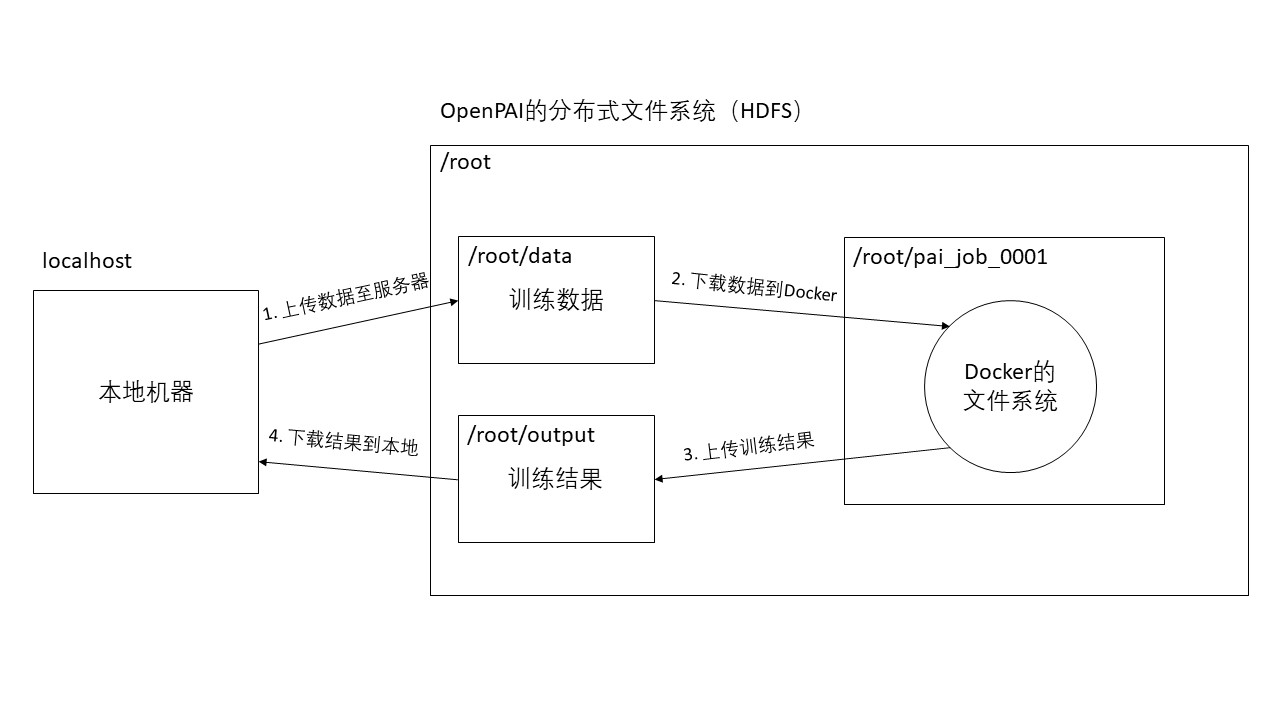
OpenPAI的每一个任务是通过创建一个独立的Docker环境进行的,Docker的文件系统与服务器的文件系统是隔离的,所以在Docker中无法通过相对路径或绝对路径直接访问到我们需要训练的数据。除了共享文件夹以外,我们还可以通过HDFS方式上传和下载数据。具体流程可以参考下图。
上传数据⚓︎
为了上传数据方便,我们将usr_dir和data_dir合并为一个文件夹,目录结构如下。
data \
__init__.py
merge_vocab.py
train.txt.up.clean
train.txt.down.clean
merge.txt.vocab.clean
但是,需要注意的是,在后续训练的目录定义中,需要将t2t_usr_dir和data_dir都指定为该data目录。
我们可以直接在HDFS EXPLORER中选择文件夹后右键,选择上传文件或文件夹。
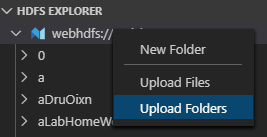
我们只需要将预处理完后的data文件夹上传至相应的目录即可。在此,我们选择上传到/demo/data,当然,你也可以上传到其他目录,该目录在后续下载数据到Docker时会使用到。
新建文件⚓︎
要提交训练任务,我们需要新建如下几个文件: * train.sh * run_samples.py * new_job.pai.json
以上文件(除new_job.pai.json外)会随任务的提交自动上传至服务器(需要配置.vscode/settings.json,后续会提到),同时也会自动下载到Docker环境中,因此我们可以在Docker中访问到它们,这里面包含了训练任务的脚本。
1. train.sh⚓︎
此为用于训练的脚本,包含了tensor2tensor的安装,以及执行训练的命令。
#!/bin/bash
HOME_DIR=$(cd `dirname $0`; pwd)
echo $HOME_DIR
cd $HOME_DIR
# install tensor2tensor
export LC_ALL=C
pip3 install tensor2tensor==1.14.1
pip3 install requests==2.21.0
# set environment
TRAIN_DIR=${HOME_DIR}/output
LOG_DIR=${TRAIN_DIR}
DATA_DIR=${HOME_DIR}/data
USR_DIR=${DATA_DIR}
PROBLEM=translate_up2down
MODEL=transformer
HPARAMS_SET=transformer_small
mkdir -p ${TRAIN_DIR}
# generate data
echo start generate data...
t2t-datagen \
--t2t_usr_dir=${USR_DIR} \
--data_dir=${DATA_DIR} \
--problem=${PROBLEM}
# train model
setting=default
echo start training...
t2t-trainer \
--t2t_usr_dir=${USR_DIR} \
--data_dir=${DATA_DIR} \
--problem=${PROBLEM} \
--model=${MODEL} \
--hparams_set=${HPARAMS_SET} \
--output_dir=${TRAIN_DIR} \
--keep_checkpoint_max=1000 \
--worker_gpu=1 \
--train_steps=200000 \
--save_checkpoints_secs=1800 \
--schedule=train \
--worker_gpu_memory_fraction=0.95 \
--hparams="batch_size=1024" 2>&1 | tee -a ${LOG_DIR}/train_${setting}.log
2. run_samples.py⚓︎
此为用于执行任务的运行脚本,包含了下载数据至Docker,调用train.sh脚本开始训练,以及完成训练以后的数据上传。这是我们训练任务程序运行的入口,在OpenPAI开始任务后,我们会首先调用此脚本,具体调用方法在new_job.pai.json中介绍。
注意这里需要替换以下几个变量:
1. hdfs_url : 替换为openPAI中的pai-master结点
2. hdfs_user_name :替换为你的用户名
3. root_dir :替换为存放数据的根目录,用于下载训练数据至Docker。在此,由于我们将数据上传至了/demo/data,因此将root_dir替换为/demo。项目训练完成后会将结果上传至/demo/output。
import os
import sys
import hdfs
import subprocess
hdfs_url = "YOUR_HDFS_URL"
hdfs_user_name = "YOUR_HDFS_USERNAME"
root_dir = "YOUR_PROJECT_ROOT_DIR"
class HDFSHelper(object):
def __init__(self, hdfs_url, hdfs_user_name, hdfs_root):
self.__client = hdfs.InsecureClient(hdfs_url, root=hdfs_root, user=hdfs_user_name)
self.__client.set_permission(hdfs_root,777)
def Download(self, hdfs_path, local_path):
print("Downloading from {} to {}".format(hdfs_path, local_path))
os.makedirs(local_path, exist_ok=True)
self.__client.download(hdfs_path, local_path)
def Upload(self, local_path, hdfs_path):
print("Uploading from {} to {}".format(local_path, hdfs_path))
self.__client.makedirs(hdfs_path)
self.__client.upload(hdfs_path, local_path, overwrite=True)
hdfsHelper = HDFSHelper(hdfs_url, hdfs_user_name, root_dir)
# Downloading data
hdfsHelper.Download(os.path.join(root_dir, "data"), ".")
# Call train.sh
subprocess.call("./train.sh", shell=True)
# Uploading data
jobName = os.environ['PAI_JOB_NAME']
output_dir = os.path.join(root_dir, "output", jobName)
hdfsHelper.Upload("./output/", output_dir)
3. new_job.pai.json⚓︎
此为用于提交训练任务的配置文件,其中taskRoles字段下的command为openPAI创建完Docker环境后开始执行的命令,image字段用于指定docker hub中的Docker镜像。
{
"jobName": "train_couplet_demo",
"image": "vzich/poet:tensorflow",
"codeDir": "$PAI_DEFAULT_FS_URI/$PAI_USER_NAME/$PAI_JOB_NAME",
"taskRoles": [
{
"name": "demo_001",
"taskNumber": 1,
"cpuNumber": 2,
"gpuNumber": 1,
"memoryMB": 8192,
"command": "pip3 --quiet install future && cd $PAI_JOB_NAME && ls -al && chmod +x train.sh && python3 run_samples.py"
}
]
}
我们在此文件中配置command为
pip3 --quiet install future && cd $PAI_JOB_NAME && ls -al && chmod +x train.sh && python3 run_samples.py
run_samples.py。
提交任务⚓︎
-
在提交任务之前,我们需要修改
.vscode/settings.json为:完成以后,提交任务会自动将当前目录中的.py文件和.sh文件一起上传。{ "pai.job.upload.enabled": true, "pai.job.upload.exclude": [], "pai.job.upload.include": [ "**/*.py", "**/*.sh" ], "pai.job.generateJobName.enabled": true } -
右键
new_job.pai.json,选择Submit Job to PAI Cluster。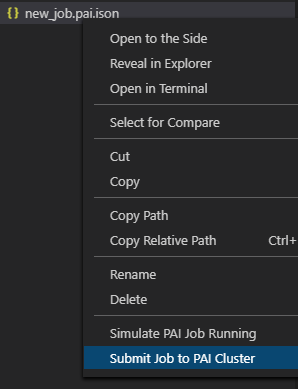
此时,就完成了任务的提交。
成功提交任务后,VS Code会将上一步新建的若干.py和.sh文件同时上传至此次任务的目录,在Docker创建完后会自动执行new_job.pai.json文件中taskRoles下的command字段内容。
下载数据⚓︎
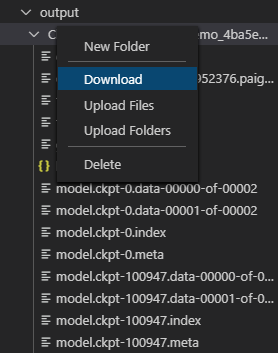
在任务运行完成后,Docker会自动销毁,对此我们在run_sample.py中实现了让Docker训练完成后自动将结果上传至服务器相应的目录。因此,我们只需要在HDFS EXPLORER的相应目录中找到我们训练的结果即可。在示例中,我们可以在/demo/output中找到训练结果。
找到对应的结果,右键可以选择下载到本地。
至此,我们便完成了OpenPAI的任务提交、训练以及获取训练结果啦。